What do airbnb guests say about New York City's neighborhoods?
In this project, I wanted to tackle two new skillsets: natural language processing and web-based data visualization. And I got lucky by stumbling on a huge, rich, and easy to access dataset: 440,000 airbnb reviews and 35,000 listing in New York City from 2008-2016, conveniently scraped by the website insideairbnb.com.
And man, is this data rich. Every listing has an average star rating, description, neighborhood, a list of amenities and a unique host ID. The reviews each have a date, unique user ID, and full text body. And it all comes in clean csvs! Yahoo!
I had a few ideas for this early on. First, I wanted to build a regression model and flask app that would let a host see how much they should charge for their property, based on the location, star rating, and amenties offered. Then I realized airbnb had already built that tool and they’d done it really well:
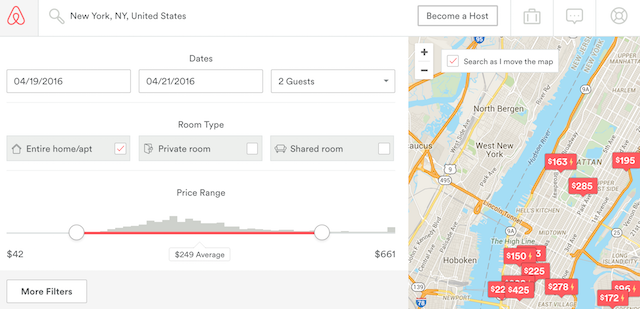 Well done, airbnb data science team. Actually, their whole blog is really good.
Well done, airbnb data science team. Actually, their whole blog is really good.
So, I tried something else instead. After playing around with LDA topic modeling and k-means clustering, I decided to use TF-IDF to look at the most common terms used relative to each neighborhood in NYC.
I used a D3 geojson of NYC’s neighborhood and linked it to a jQuery word bubble tool (found on this blog post). The result is a webpage that lets you click on a neighborhood and see what airbnb users talk about after staying there. I also threw in the average star rating and a textblob sentiment analysisof all the reviews for good measure.
 People who stay in Jamaica, Queens talk about how it’s really close to JFK.
People who stay in Jamaica, Queens talk about how it’s really close to JFK.
You can play around with the tool here: yawitzd.github.io/airbnb
In a lot of cases (like Jamaica, above), the word bubbles give you a quick overview of what it’s like to stay in that neighborhood. Large bubbles like “airport” and “close JFK” are pretty self-explanatory. But other terms like “snack” and “fridge” indicate that there’s a host in that area who likes keeping his guests well fed.
There’s still some refining I want to do. For example, I still want to take the neighborhood’s name out of each neighborhood’s list. (‘Soho’ drowns almost everything else in Soho, with the exception of ‘loft’). I also want to find a way to keep common n-grams from repeating themselves as 1- 2- and 3- grams. The Upper West Side is a good example of that:
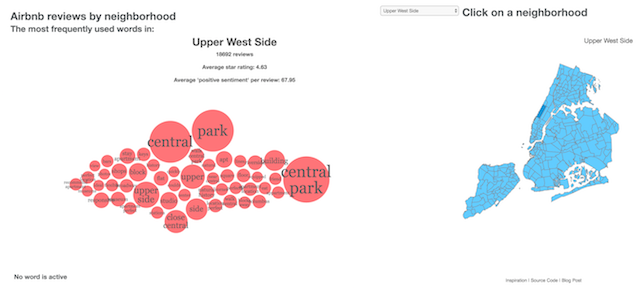 Central, Park, Central Park, Upper Side, and Side, are all important, you say?
Central, Park, Central Park, Upper Side, and Side, are all important, you say?
But this isn’t a bad place to start. All this code is on my github if you want to look deeper.
And some of the results of the LDA clustering is kind of interesting. Check them out here.